什么是Token
Token是什么?
Deepseek给出的解释是:
token 是模型用来表示自然语言文本的基本单位,也是我们的计费单元,可以直观的理解为“字”或“词”;通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token。
一般情况下模型中 token 和字数的换算比例大致如下:
- 1 个英文字符 ≈ 0.3 个 token。
- 1 个中文字符 ≈ 0.6 个 token。
阿里云的解释是
大模型以 Token 为单位处理输入和输出。一个 Token 可能是:
- **单个字符:**如
A、我- **完整的单词:**如
large、Model- **长单词的一部分:**一个长单词通常会被拆分为多个 Token,拆分的过程称为分词。
根据经验,平均 1 个汉字约对应 1.5-2 个 Token;1 个英文字母约对应 0.25 个 Token;1 个英文单词约对应 1.3 个 Token:
阿里云百炼:约 4-5 个 TokenHello World:约 2 个 Token每个模型都有最大输入和输出 Token 数(详见模型列表),超过限制会导致请求失败。
OpenAI的解释是:
Token 是 OpenAI 模型处理文本的基本单位。根据语言和上下文,它们可以短到单个字符,也可以长到一个完整的单词。空格、标点以及单词的一部分都会计入 token 数。这就是 API 在生成回复之前,内部对你的文本进行切分的方式。
对英文有一些实用的经验法则:
- 1 个 token ≈ 4 个字符
- 1 个 token ≈ ¾ 个单词
- 100 个 token ≈ 75 个单词
- 1–2 句 ≈ 30 个 token
- 1 段 ≈ 100 个 token
- 约 1,500 个单词 ≈ 2,048 个 token
不同语言的分词方式会有所差异。例如,“Cómo estás”(西班牙语,意为“你好吗”)10 个字符却包含 5 个 token。非英文文本往往会产生更高的 token/字符比,这可能会影响成本和限制。
Claude Code的解释是
Token是语言模型的最小独立单元,可以对应于单词、子词、字符甚至字节(在 Unicode 的情况下)。
对于 Claude,一个Token大约代表 3.5 个英文字符,但确切数量可能因使用的语言而异。在”文本”级别与语言模型交互时,Token通常是隐藏的,但在检查语言模型的确切输入和输出时变得相关。
当向 Claude 提供要评估的文本时,文本(由一系列字符组成)被编码为一系列Token供模型处理。较大的Token在推理和预训练期间实现数据效率(并在可能时被使用),而较小的Token使模型能够处理不常见或从未见过的词语。
Tokenize方法的选择会影响模型的性能、词汇量大小以及处理词汇表外词语的能力。
如果想要了解Token对于AI本身到底是什么东西,可以看看NVIDIA的说明:
什么是 Tokenization(令牌化/分词)?
无论是 Transformer AI 模型 在处理文本、图像、音频剪辑、视频还是其他模态,它都会将数据翻译成 Token。这个过程被称为 Tokenization。
高效的 Tokenization 有助于减少训练和推理所需的计算能力。目前有多种 Tokenization 方法,而针对特定数据类型和用例定制的 Tokenizer(分词器)可以只需要较小的词汇表,这意味着需要处理的 Token 更少。
对于大语言模型(LLMs),短单词可能由单个 Token 表示,而较长的单词可能会被拆分为两个或更多 Token。
例如,“darkness”(黑暗)这个单词会被拆分为两个 Token:“dark” 和 “ness”,每个 Token 都有一个数值表示,例如 217 和 655。反义词 “brightness”(光明)同样会被拆分为 “bright” 和 “ness”,对应的数值表示为 491 和 655。
在这个例子中,“ness” 所关联的共享数值可以帮助 AI 模型理解这些词可能有共同之处。在其他情况下,Tokenizer 可能会根据上下文中的含义,为同一个词分配不同的数值表示。
例如,“lie” 这个词可以指代躺下的姿势(躺),也可以指代说不真实的话(撒谎)。在训练期间,模型会学习这两个含义之间的区别,并为它们分配不同的 Token 编号。
对于处理图像、视频或传感器数据的视觉 AI 模型,Tokenizer 可以帮助将像素(pixels)或体素(voxels)等视觉输入映射为一系列离散的 Token。
处理音频的模型可能会将短片段转化为声谱图(spectrograms)——即声音随时间波动的视觉描述,然后将其作为图像进行处理。其他音频应用可能会专注于捕捉包含语音的剪辑含义,并使用另一种捕捉 语义 Token(semantic tokens) 的 Tokenizer,这些 Token 代表语言或语境数据,而不仅仅是声学信息。
Token 在 AI 训练中如何使用?
训练 AI 模型始于对训练数据集的 Tokenization。
根据训练数据的大小,Token 的数量可能达到数十亿或数万亿——而且根据预训练缩放定律(pretraining scaling law),用于训练的 Token 越多, AI 模型的质量就越好。
当 AI 模型进行预训练时,它会通过展示一组样本 Token 并被要求预测下一个 Token 来进行测试。根据其预测是否正确,模型会自我更新以改进下一次猜测。这个过程不断重复,直到模型从错误中吸取教训并达到目标准确率水平,即所谓的“模型收敛”。
预训练之后,模型会通过**后训练(post-training)**进一步改进,在与部署用例相关的 Token 子集上继续学习。这些可能是包含法律、医学或商业等领域特定信息的 Token,或者是帮助模型适配特定任务(如推理、聊天或翻译)的 Token。目标是让模型生成正确的 Token,从而根据用户的查询提供正确的响应——这种技能更广为人知的名称是**推理(inference)**。
Token 在 AI 推理与推理(Reasoning)中如何使用?
在推理过程中,AI 接收一个提示(prompt)——根据模型的不同,这可能是文本、图像、音频、视频、传感器数据甚至是基因序列——并将其翻译成一系列 Token。模型处理这些输入 Token,生成作为 Token 的响应,然后将其翻译回用户预期的格式。
输入和输出语言可以不同,例如在将英语翻译成日语的模型中,或者在将文本提示转换为图像的模型中。
为了理解一个完整的提示,AI 模型必须能够同时处理多个 Token。许多模型有一个指定的限制,称为上下文窗口(context window)——不同的用例需要不同的上下文窗口大小。
一个能同时处理几千个 Token 的模型可能足以处理单张高分辨率图像或几页文本。而拥有数万个 Token 上下文长度的模型,则可能总结一整本小说或长达一小时的播客节目。一些模型甚至提供一百万或更多 Token 的上下文长度,允许用户输入海量数据源供 AI 分析。
**推理 AI 模型(Reasoning AI models)**是 LLM 的最新进展,它们通过以不同于以往的方式对待 Token 来解决更复杂的查询。在这里,除了输入和输出 Token 之外,模型在思考如何解决给定问题时,会在几分钟或几小时内产生大量的**推理 Token(reasoning tokens)**。
这些推理 Token 允许模型对复杂问题给出更好的回答,就像人在处理问题时如果有充足的时间思考会给出更好的答案一样。每个提示对应的 Token 增加量可能比传统 LLM 的单次推理高出 100 倍以上——这是测试时缩放(test-time scaling)(又称“长思考”)的一个典型例子。
Token 如何驱动 AI 经济学?
在预训练和后训练期间,Token 等同于对智能的投资;而在推理期间,它们驱动着成本和收入。因此,随着 AI 应用的激增,新的 AI 经济学原则 正在显现。
AI 工厂的建立是为了维持高容量的推理,通过将 Token 转化为可变现的见解来为用户“制造智能”。这就是为什么越来越多的 AI 服务根据消耗和生成的 Token 数量来衡量其产品的价值,并根据模型的 Token 输入和输出速率提供计费方案。
一些 Token 定价计划为用户提供在输入和输出之间共享的固定数量 Token。基于这些 Token 限制,客户可以使用仅消耗几个 Token 的短文本提示作为输入,来生成耗费数千个 Token 的长篇 AI 响应作为输出。或者,用户也可以将大部分 Token 花在输入上,为 AI 模型提供一组文档以总结成几个要点。
为了服务大量并发用户,一些 AI 服务还设置了 Token 限制,即为单个用户每分钟生成的最大 Token 数量。
Token 还定义了 AI 服务的用户体验。首字时间(Time to first token),即用户提交提示到 AI 模型开始响应之间的延迟,以及 Token 间延迟(inter-token latency),即后续输出 Token 生成速率,决定了终端用户体验 AI 应用输出的感受。
每个指标都涉及权衡,而最佳平衡点由用例决定。对于基于 LLM 的聊天机器人,缩短首字时间有助于维持交流节奏,避免不自然停顿,从而提高用户参与度。优化 Token 间延迟可以使文本生成模型匹配普通人的阅读速度,或者让视频生成模型达到理想的帧率。对于从事长思考和研究的 AI 模型,重点则更多放在生成高质量 Token 上,即使这会增加延迟。
开发者必须在这些指标之间取得平衡,以提供高质量的用户体验和最优的 吞吐量(throughput)(即 AI 工厂能够生成的 Token 数量)。
为了应对这些挑战,NVIDIA AI 平台 提供了丰富的软件、微服务和蓝图,以及强大的加速计算基础设施——这是一个灵活的全栈解决方案,使企业能够进化、优化并扩展 AI 工厂,从而在各行各业生成下一波智能浪潮。
了解如何在不同任务中优化 Token 使用,可以帮助开发者、企业甚至终端用户从其 AI 应用中获取最大的价值。
之所以有这个问题,主要是因为B站上有人提到停止翻译Token的建议,个人觉得并不太贴切。实际上,我们可以看到,在大多数企业中,Token有没有一个准确的翻译词,要么就是机器翻译的令牌,要么就是老老实实直接用英语的Token,很难有一个中文中的翻译。然而在文化传播领域,例如《人民日报》就使用了“词元”这个翻译。
怎么理解词元?简单来说,词元是人工智能大模型为了高效处理数据,把数据进行拆分后的“最小信息载体”,可以理解为“字/词片段/符号”等。比如“我爱中国!”,可拆分成“我”“爱”“中国”“!”4个词元。
如果说互联网时代信息传输的核心度量是“流量”,那么人工智能时代,这一关键指标正变为词元——用户输入的每一个字,模型生成的每一段话、识别的每一幅图像,都在消耗词元。
看似很抽象,实际上,每一次词元消耗都对应着真实的场景交互——可能是银行智能客服作出的一笔贷款咨询,是汽车智能座舱处理的一句语音指令,或是编程助手输出的数行复杂代码。词元消耗量爆发式增长,意味着越来越多人工智能应用落地,越来越多个人用户、企业客户在使用智能工具解决问题、提高效率。词元消耗增长与应用落地强绑定的特性,使其成为衡量人工智能产业景气度的重要晴雨表。
如果按照视频的观点,由于Token并不是用字或者词切分的,而是由出现频率和压缩效率动态决定的,而元是构成某类事物最小、不可再分的基本单位,同一个字或者不同的词在不同的上下文可能会拆分为不同的Token,也可能会和其他的字合成一个Token,那这里元并不可以准确描述Token。
首先一个问题是“元”可以不可以准确描述Token,如果按照《人民日报》的解读,Token是数据进行拆分后的“最小信息载体”,那么它本身就是一种信息元。其次,同一个字或者不同的词在不同的上下文可能会拆分为不同的Token,也可能会和其他的字合成一个Token,这种现象本身也是取决于“出现频率和压缩效率”——但是在大多数情况下,一个Token所承载的信息小于一个汉字,某种意义上来说,绝大多数情况下Token对于汉语可以是比字更小的单位。
那么什么情况下,Token可能会比一个汉字大呢?这一般会发生在高频率的专有名词的情况下,譬如“阿里巴巴”,逐个字翻译本身不存在任何意义;还有一个典型的例子就是“苹果”,这个词实际上是一个音意结合的翻译词,“苹”来自梵语而“果”来自汉语,如果按照“哟哟鹿鸣,食野之苹”的解释,那么“苹”应该是单独一个Token,然而“苹果”的“苹”除了表示声音没有任何特别含义,脱离了“苹果”这个单词。当然,如果细究起来,汉语可以到处都是“专有名词”,还有很多耳熟能详的成语,譬如一个知名的网站“术语在线”,你是可以把它分为“术语”和“在线”两个Token,还是“术语在线”一个Token,甚至一个字一个Token,这都是取决于你的Tokenization的过程,也就是所谓的“出现频率和压缩效率”。
最后,为什么AI的Token还可以比一个字小呢?这主要和汉字的编码有关,汉字在计算机中存储一般是一个汉字两个字节,但是Tokenization多数情况下都是按照字节划分的,所以对于大多数情况下两个字节并不需要2个Token来对应,实际上压缩了汉字的Token生成比例。汉字中也存在大量的生僻字,如果在现存的词汇表中无法找到对应,Tokenizer会将其拆分为2-3个Token,这又会拉高Token的生成比例。
Tokenizer根据一个现成的词表统计Token,如果你的输入miss了词表,就会大大增加所产生的Token量;换言之只要词表够大,Token的生成比例也会相应的降低,这其实只是一个平衡上的取舍问题。对于Transformer而言,这只是自然语言离散化的结果,Tokenzier越细就会导致计算量越大,Token越少会丧失一部分的精度,但也可以提高计算速度。就目前而言,一个汉字对应的Token既有阿里云的1.5-2.0个左右,也有Deepseek所说的0.6个左右,都是取决于数据压缩和Tokenizer的配置。
如何翻译Token?
我们可以看到,Token实际上和字、词都没有本质联系,它只是一个占用词表的换算单位,你占了词表一个位置就有一个Token,如果你在词表没有位置,那么就归到几个位置凑合。词元和字元的这种翻译非常符合我对汉语翻译的理解,汉语一般会用既有的概念来解释不同的概念,很少会直接引入完整的外来语。
我感到比较有趣的一个点是,Token也不算是英语中的特别常用的单词,又怎么会在计算机领域得到如此大规模的应用。这里可以看看Google Books Ngram Viewer,看看Token的具体词用是怎么来的。
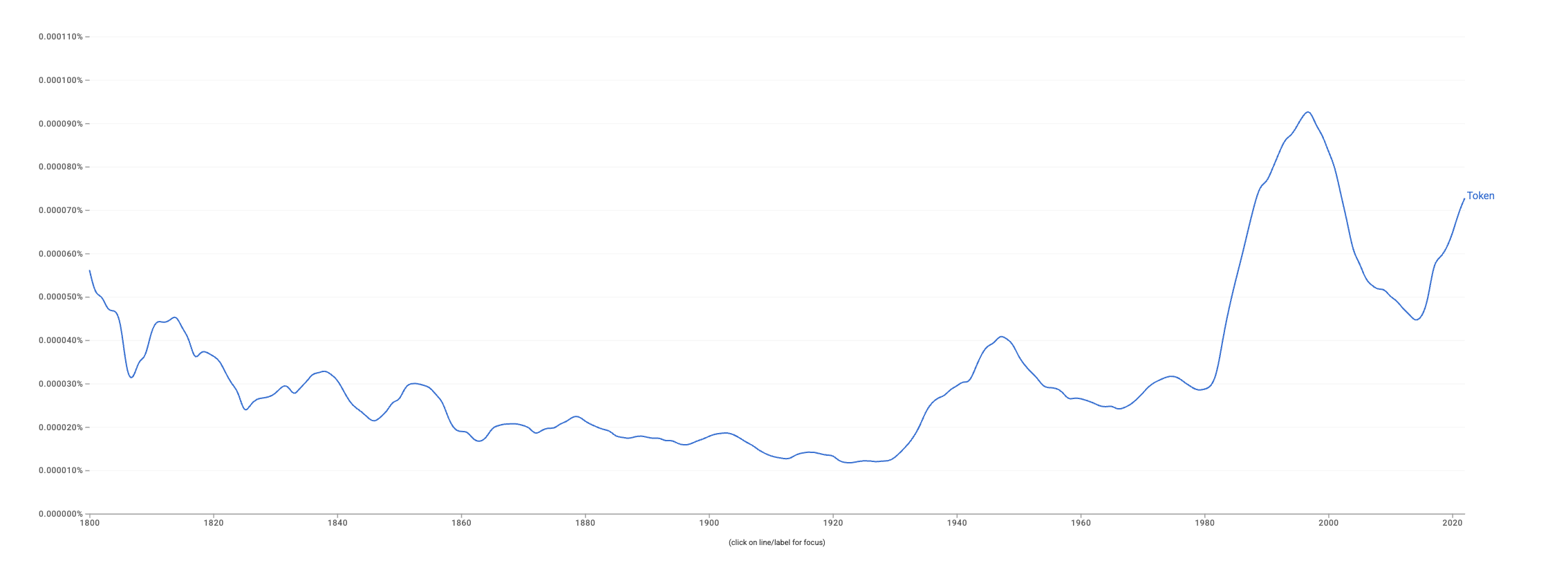
从Ngram Viewer可以看到,Token的使用在1800年以前、1946年、1996年分别有几次高峰,那么这个时候Token都是什么意思呢?这里又要去问问词典如何解释了。OED对Token有3个词条,其中最后一个词条频率最高,点进去一看这个词的原型是Take,估计是Taken的古英语用法了;另外一个则是真正的Token,有名词和动词两个词条,动词词条还在编纂中,那么就只能看看名词。
根据OED的词源学统计,Token这个词来自于古英语,为星相学和宗教学领域使用,在17世纪进入了金融和印刷业,19世纪开始应用于纺织业和采矿业,20世纪开始引入到了语言学和计算机领域。在古英语中,这个词可以表示证据、象征、表象等等,在晚期古英语中表示“observable characteristic or action indicating an inner state; means of identifying a person”(对于某个内在状态可观察的动作或者特征;识别某个人的方法),而到了1590年代开始表示某种类似钱币的金属片(代币)。Token这个词和Take、Touch都是同源,最早应该是一种拟声词,可能就是我们敲击木头的声音,像是Tiktok的Tok也是这种声音。古代日耳曼人会通过敲击木头进行占卜,因此这个词也被借入芬兰语中,芬兰语Taika的意思就是占卜。
英语的Token融合了两种意思,既有古老的信号、标记、证据,也有表示预兆、惊奇、奇迹,可以说作为一个严谨的学术用语颇具浪漫主义色彩。17世纪的英国正是多事之秋,伊丽莎白一世治下的英国和西班牙长期鏖战,新旧教之间的冲突席卷了整个欧洲,英国内战之后又遇到了天主教复辟和伦敦大火,直到1688年的光荣革命才恢复了稳定的局面。在这种背景下,英国政府逐渐放弃了金银币以外的货币发行,所以零钱短缺成为了17世纪的常态,为此英国的小摊小贩都开始自己做一些黄铜皮作为和自己兑换商品的凭证——想象一下,如果你有一枚银币,你可以从商贩那里买一些代金券,换好商品之后再卖出去——这种凭证也就变成了一种代币,这种代币就叫Token。在英国内战之后至1672年政府取缔Token的发行,这种没有明确面值的代币风靡一时,从此以后就变成了官方货币短缺之后私人发行的替代货币的代名词,大有我们今天虚拟货币的样子。

第二次世界大战结束后,欧洲和英国都陷入物质短缺的问题,配给制而来的物质兑换券也成为了当时的经济学现象。
对于印刷术而言,模具(Type)印出来的东西就是Token,伦敦印刷业工人还会按照印刷出来的张数计算Token,一个 Token 等于 250 张印好的纸,每天根据印刷的Token数量换算成工资。别人是每天多少Token的产出,现在反过来我们要为用了多少Token付钱。
语言学家可能是借鉴了这个例子,美国实用主义哲学家为了区分具体的、一次性的事件与其背后的抽象形式,将前者称之为Token,后者称之为Type:
估算印刷书籍内容量的常用方法是计算字数。通常一页纸上会有大约二十个“the”,当然,它们算作二十个单词。然而,在“单词”的另一种含义中,英语中只有一个词“the”;而且这个词不可能出现在纸上,也不可能以任何声音被听到……这种形式,我建议称之为“Type”。一个单独的……对象……例如一本书的某一页上某一行的某个词,我姑且称之为“Token”。……为了能够使用字型,它必须被包含在一个标记中,该标记将成为字型的标志,从而也成为字型所指对象的标志。
这一个说法也影响到了后来的生成句法学派。在乔姆斯基的算法中,词法分类(如名词 $N$、动词 $V$)以及词表中的词项(如 “apple”)被视为 Type。它们是抽象的符号,是规则生成的模板;当语法规则最终“跑”完,生成一个具体的句子时,末端生成的每一个具体的词就是 Token;乔姆斯基认为语言学研究的终极目标是 Type(背后的生成规则),而 Token 只是这些规则在现实中留下的碎片。乔姆斯基不喜欢概率建模,他有一个经典的例子:
Colorless green ideas sleep furiously.

这句话是语法正确、语义荒谬的典型,乔姆斯基反驳很多语言学家认为我们之所以觉得一句话“通顺”,是因为我们以前听过类似的词组,这是一种统计上的高概率,而这种造句方法肯定可以造出来以往闻所未闻的新句子,而大众却会觉得这个句子是合理的。乔姆斯基借此来表达,语言学家应该专注于研究Type而不是Token,统计Token的频率对于解析语法毫无意义。在乔姆斯基的观点中,语言是某种生成的表层结构,而语言本身来自于大脑内的深层结构,大脑可以通过某种转换语法(Transformational grammar)将大脑深层结构的东西转化为我们所使用的语言。对于同义的句子,他们有一个共同的深层结构和不同的表层结构,而对于歧义的句子则是相反。对于人类而言,语言只是一种表象,想要表达的意思——或者大脑内的抽象意图才是关键,只需简单的规则就可以从共同的抽象意图涌现出无数的语言学现象。
既然乔姆斯基这么讨厌Token,那为什么要提到他?因为我们的编译原理就是由他的生成语法学派奠定的,编译器只需要几条简单的规则就可以实现大量可以操作的复杂代码,所以对于编译器而言也是在执行乔姆斯基语法分析的过程,编译器实现的是将Token转化为Type,然后生成可执行文件的过程。当时的人工智能也主张基于规则的涌现,以制定元规则和专家系统为主要方向,所以语言模型在当时属于边缘的边缘——直到弗雷德里克·杰利内克开始在IBM领导语言识别工作,他有一句名言:
Every time I fire a linguist, the performance of the speech recognizer goes up
每当我开除一名语言学家,语音系统的识别率就会上升。
杰利内克的专业是EE,专攻信息论,但是他的老婆是语言学学生,因此他经常和老婆去听乔姆斯基上课。他将信息论引入了语言学领域,将语言视作一般的信号输入,将语言的输出视作一种随机过程,引入了**隐马尔可夫模型(HMM)**来处理语音识别和翻译,这是人类第一次大规模用纯数学(概率论)来解决语言问题。由于这种做法过于成功,1990年的NLP基本上脱离了乔姆斯基的生成语法学派,彻底走向了概率统计的道路。
从此以后,NLP不在需要刻意的识别Type,而只留下了Token。
NLP时代的Token
在乔姆斯基时代的AI是什么样子的?有一个很好的例子就是现在的游戏人机,人机一般有着固定的行为模式,严格遵守开发者给他们设定的规则——譬如血条要清空的时候,人机就会主动执行规避动作,主动逃跑,反过来经常会有人钻人机的空子,卡人机的bug。这种不会学习、由有限规则组成的AI也被称作GOFAI,Good Old-fashioned AI,也就是对今天来说又老又过时的AI。